Data Structure: tree
Table of Contents
简要介绍 #
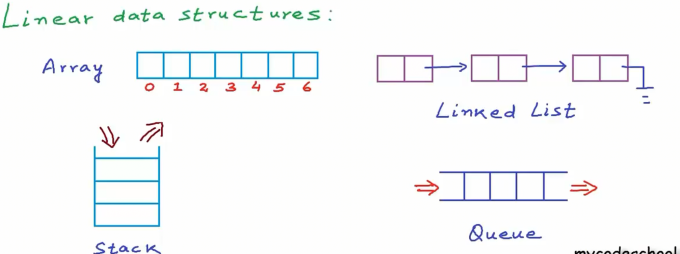
之前讨论的数据结构:数组、链表、栈和队列在逻辑上都属于线性结构。这些本质上都是数据按照顺序排列的不同集合类型,如下图所示,这些结构都有明显的逻辑起点和终点。
- 数据类型特性:特定数据结构可能最适配某种数据类型
- 操作成本:在一般情况下,我们是希望优化高频操作的成本,例如对于需要频繁检索的列表,可将其存储为排序数组,这样就可以执行二分查找等操作
- 内存消耗也是一个主要的因素,有时是需要降低内存占用
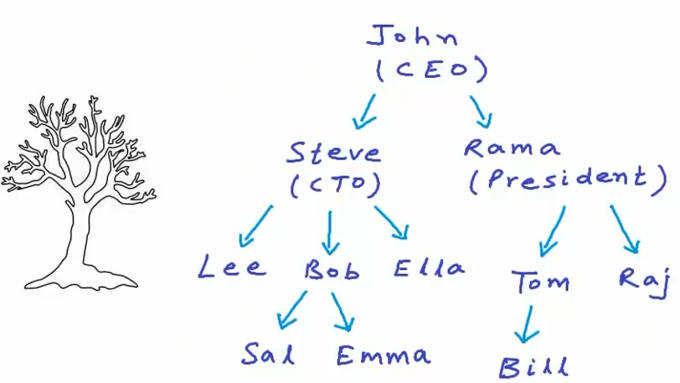
树结构常用于表示层次化数据,例如展示一个企业组织架构中人员层级关系时,可这样呈现,下图是一家公司的组织层级示意
树中的术语 #
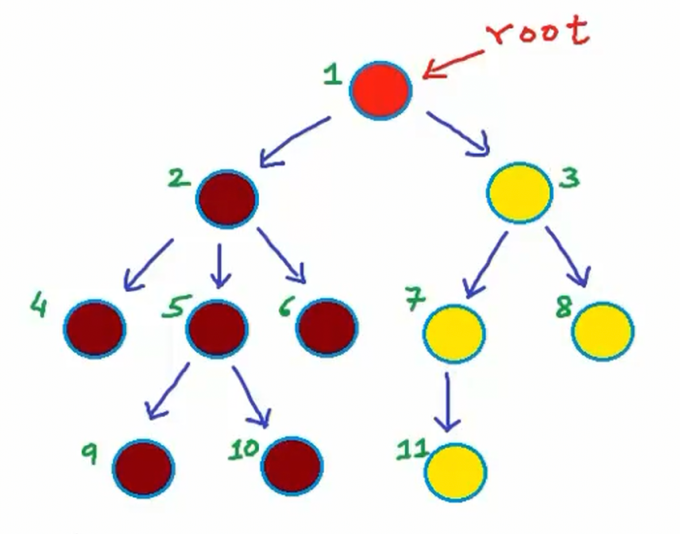
将上图中的各个节点进行编号,以便后续引用。仅仅是为了方便讲解,并不代表确定的顺序关系
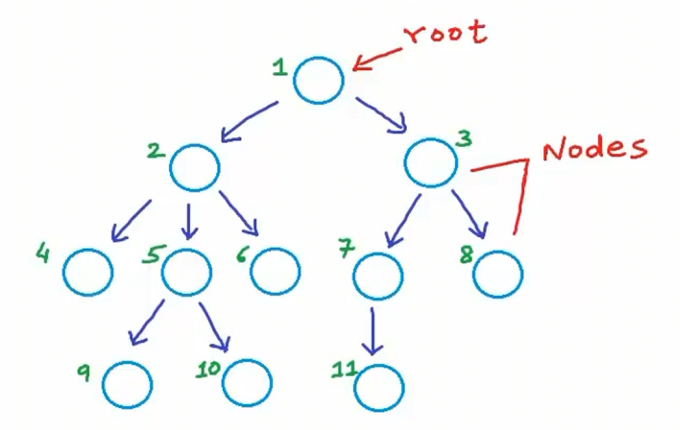
- 问题一:节点4和9的共同祖先是哪些节点?节点4的祖先节点是节点1、2,节点9的祖先节点是节点1、2、5,那么它们的共同祖先节点是节点1、2。
- 问题二:节点6和7是否为兄弟节点?不是兄弟节点,因为它们的父节点不同,但是它们有另外一层关系,它们是堂兄弟。父节点不同但祖父节点相同的节点可互称为堂兄弟节点。节点3是节点6的叔节点 – 因为它是节点2(节点6的父节点)的兄弟节点。
树的若干特性 #
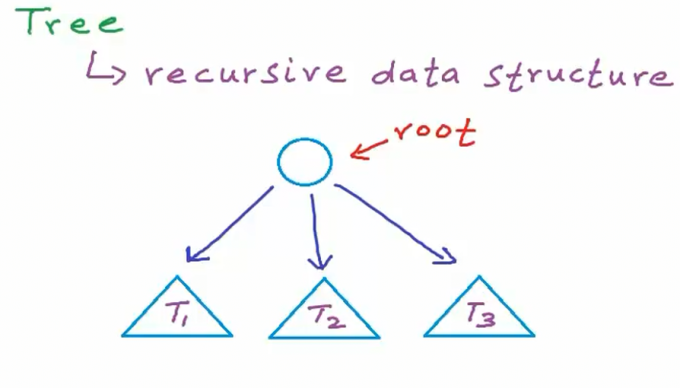
树可定义为递归数据结构,其递归定义为由根节点及若干子树构成的结构。
节点与边的关系 #
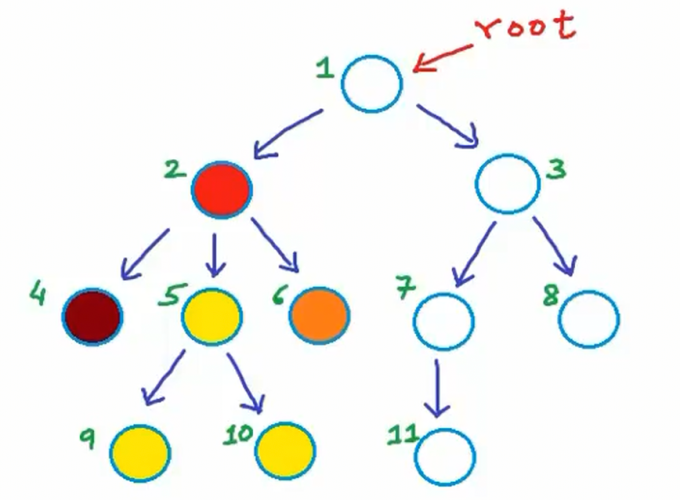
接下来讨论的特性是:具有n个节点的树必然包含n-1条链接(或称为边),如果大于n-1则这个树必然成环。图示中每个箭头都代表一条链接或边。除根节点外,所有节点都有且仅有一条入边,以2号节点为例,它只有一条入边,但它有三个子节点,分别是节点4、5、6,有三个出边。每条父子关系对应一条链接,因此,在有效树结构中,n个节点必然对应n-1条边。
深度和高度 #
讨论深度(depth)和高度(height)这两个属性。
深度 #
No. of edges in path from root to x
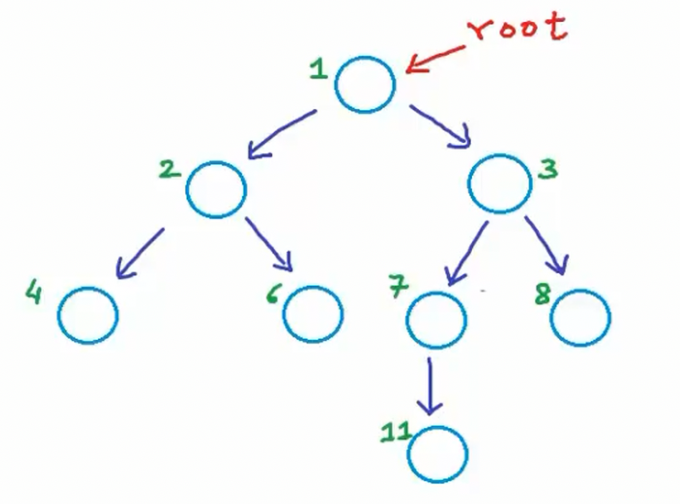
节点X的深度定义为从根节点到X的路径长度(Depth of some node X in a tree can be defined as length of the path from root to node X),路径上的每条边会使长度增加一个单位。因此也可表述为"根节点到X路径上的边数"。根节点的深度值为0. 对于5号节点,从根节点到它的路径包含两条边,因此该节点深度为2。当前树结构中:节点2和3深度为1,节点4、5、6、7、8深度为2,节点9、10、11深度为3。
高度 #
No. of edges in longest path from x to a leaf.
节点高度的定义:从该节点到叶节点的最长路径所含边数。因此节点X的高度等于从X到叶节点的最长路径中包含的边数。以节点3为例,从节点3到节点8的边数为1,从节点3到节点11的边数为2,那么从节点2到节点11的路径是最长路径,边数为2,因此节点3的高度为2。
所有叶节点的高度均为0。
那么这棵树的根节点高度是多少呢?那么你就计算从根节点到所有叶子路径的路径长度,选出一个最长的路径,它的边数就是根节点的高度,所有叶子节点分别是4、6、9、10、8、11,到4的边树为2,到9、10、11的边数为3,到8的边数为2,那么根节点的高度就为3。
根节点的高度就是树的高度。高度和深度是不同属性,节点的高度和深度可能相同也可能不同。
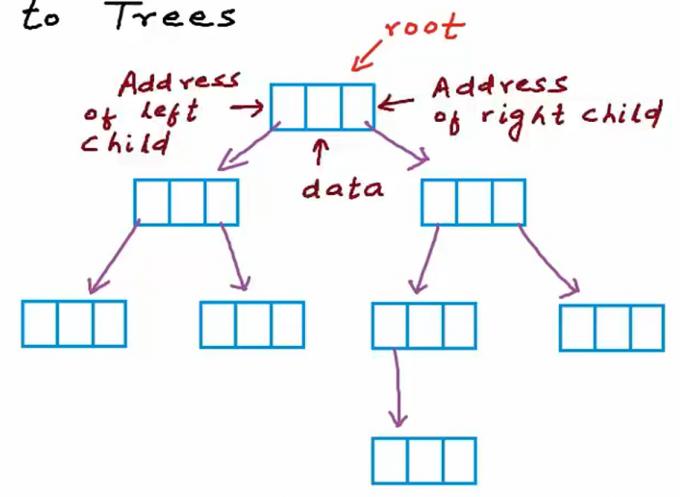
根据特性,树结构可分为多种类型,不同场景会使用不同种类的树结构。最简单常见的树结构要求每个节点最多只能只能有两个节点。如下图,这就是典型的二叉树结构,一个节点最多有两个节点。
| |
整型变量存储数据,两个指针分别指向左子树根节点(左子节点地址)和右子树根节点(右子节点地址)。仅设置两个指针是因为二叉树最多只能拥有两个子节点。这种节点的定义仅适用于二叉树。对于可包含任意数量子节点的通用树结构,会采用其他实现方式。 要记住,存储天然层级数据并非树的唯一应用场景。简单了解一下树结构在计算机科学中的典型应用:
- 存储天然层级数据(storing naturally hierarchical data)。例如磁盘驱动器中的文件系统,其文件与文件夹的层级关系就是典型的层级数据。这类数据就是以树结构进行存储的。
- 组织数据集合,实现快速搜索、插入和删除操作(organize data for quick search,insertion,deletion)。比如后续的二叉搜索树,其元素搜索时间复杂度仅仅为对数级(O(logn))
- 特殊结构的Trie树常用于字典存储,这种数据结构高效快速,可用于实现动态拼写检查功能。 还可应用于网络路由算法